
Welcome to edition #06 of the Cercle IA newsletter, the first of 2026. I wish you an excellent year, rich in learning and experimentation.
And what a better moment to mark a symbolic milestone: you are now more than 1,000 following this newsletter. Thank you to everyone who has been reading, sharing and commenting since the launch.
“Which is the best AI model?”
That is THE question that comes up in every AI training I give. My answer often disappoints: “It depends.”
Not because I refuse to take a position. But because the question starts from a flawed premise: that there would be one “best” model, universal, optimal for all uses.
It is like asking which Olympic athlete is the best. The sprinter? The marathon runner? The javelin thrower? The answer depends on the event.
In this edition:
- The podium does not tell the whole story: why AI rankings are useful but insufficient
- The AI Olympic disciplines: understanding where each model excels
- The 7 forms of “doping”: what distorts benchmarks and rankings
- The tool to test: LMarena, the arena where you judge the models yourself
From ancient Olympia to the digital arenas
776 BC, Olympia, Greece. Coroebus of Elis crosses the finish line of the stadion. He becomes the first Olympic champion in history. But was he the best athlete?
The Greeks already knew he was not. That is why they created the pentathlon: running, long jump, discus throw, javelin throw, wrestling. The true champion had to excel in several disciplines.
This obsession with objective measurement was embodied in the Olympic motto: Citius, Altius, Fortius: faster, higher, stronger.
AI benchmarks: the obsession with measuring the intelligence of AI models
Unlike a sprinter, you cannot simply time an AI. Intelligence is not one-dimensional.
That is why researchers have created benchmarks — standardised tests to measure different capabilities: language comprehension, logical reasoning, code generation, visual analysis, creativity, honesty.
2018-2020: The “stadion” era (GLUE benchmark)
GLUE (General Language Understanding Evaluation) was launched in January 2018 to measure real natural language understanding. Like the stadion, the first benchmarks measured one thing: language comprehension. But excellent comprehension does not equal good reasoning, good code or good creativity.
2020-2023: The pentathlon era (diversification of benchmarks)
The AI community recognised that models had several “muscles” to measure:
- MMLU: general knowledge (57 domains, from law to medicine)
- HumanEval: code generation
- BBH: complex reasoning
- HELM: holistic evaluation across 42 scenarios
2023-2025: The modern AI Games era
Like the Paris 2024 Olympics, which brought together 32 sports and 329 events, there are today more than 50 AI model benchmarks. And there is no universal AI champion model. Each discipline reveals its own podium.
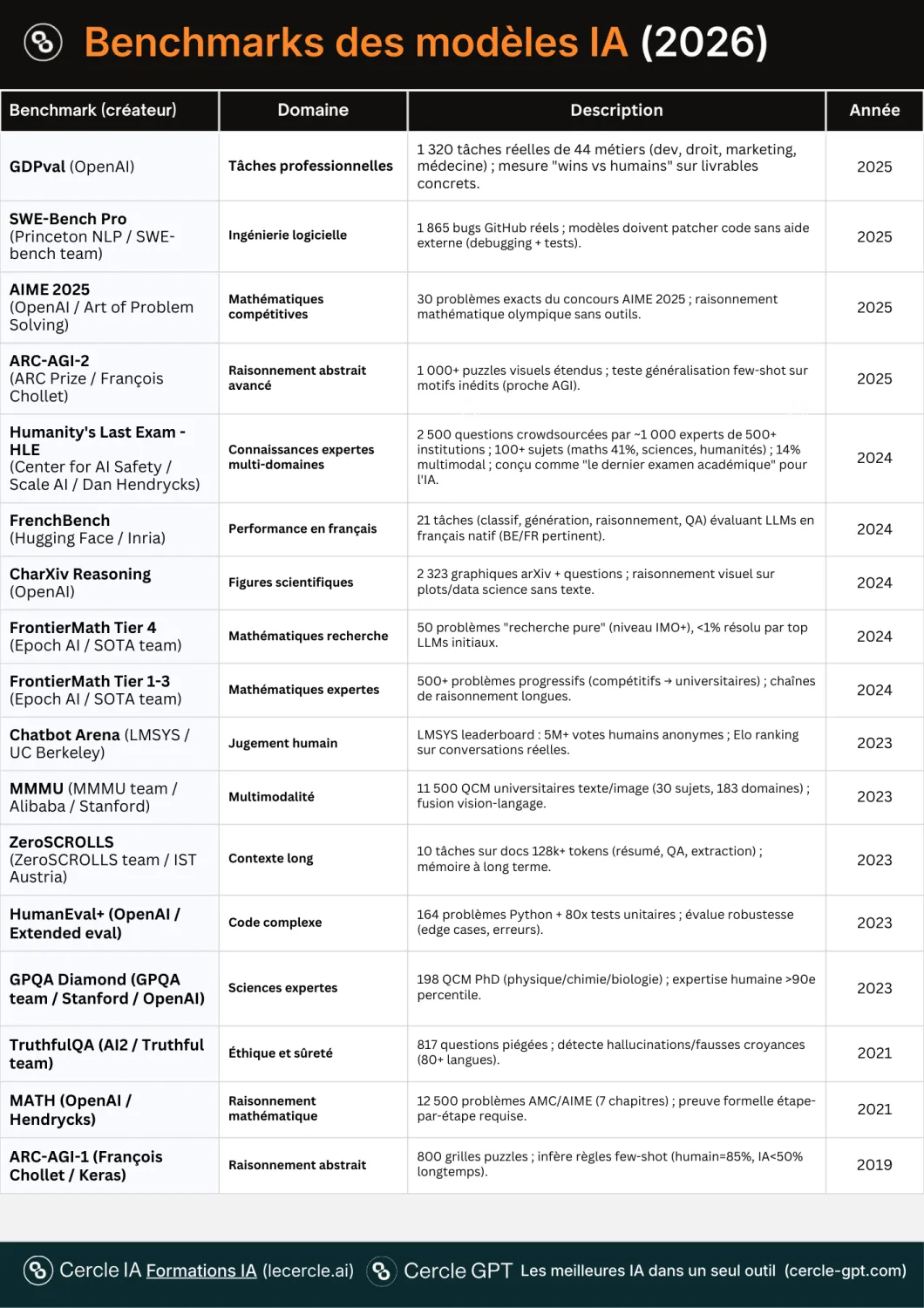
Seven forms of AI model “doping”
Ben Johnson, 1988, Seoul. World record. Gold medal. Then disgrace: positive doping test, title stripped.
In AI, comparable practices distort benchmarks:
- Data contamination: models have often seen benchmark questions during their training. They recite, they do not reason.
- Benchmark over-fitting: models are tuned to succeed on specific tests, to the detriment of their behaviour outside the benchmark.
- Strategic result selection: labs highlight favourable benchmarks and ignore others.
- Benchmark design bias: certain tests favour certain architectures or families of models.
- Absence of oversight and governance: no limit on the number of attempts, no appeals procedure.
- Benchmark saturation and obsolescence: many remain frozen while models progress rapidly.
- Data bias and linguistic dominance: the over-representation of English distorts results.
These flaws blur the scientific signal. Researchers write that current evaluation practices are a “minefield.”
SOTA: the moving podium of state-of-the-art AI models
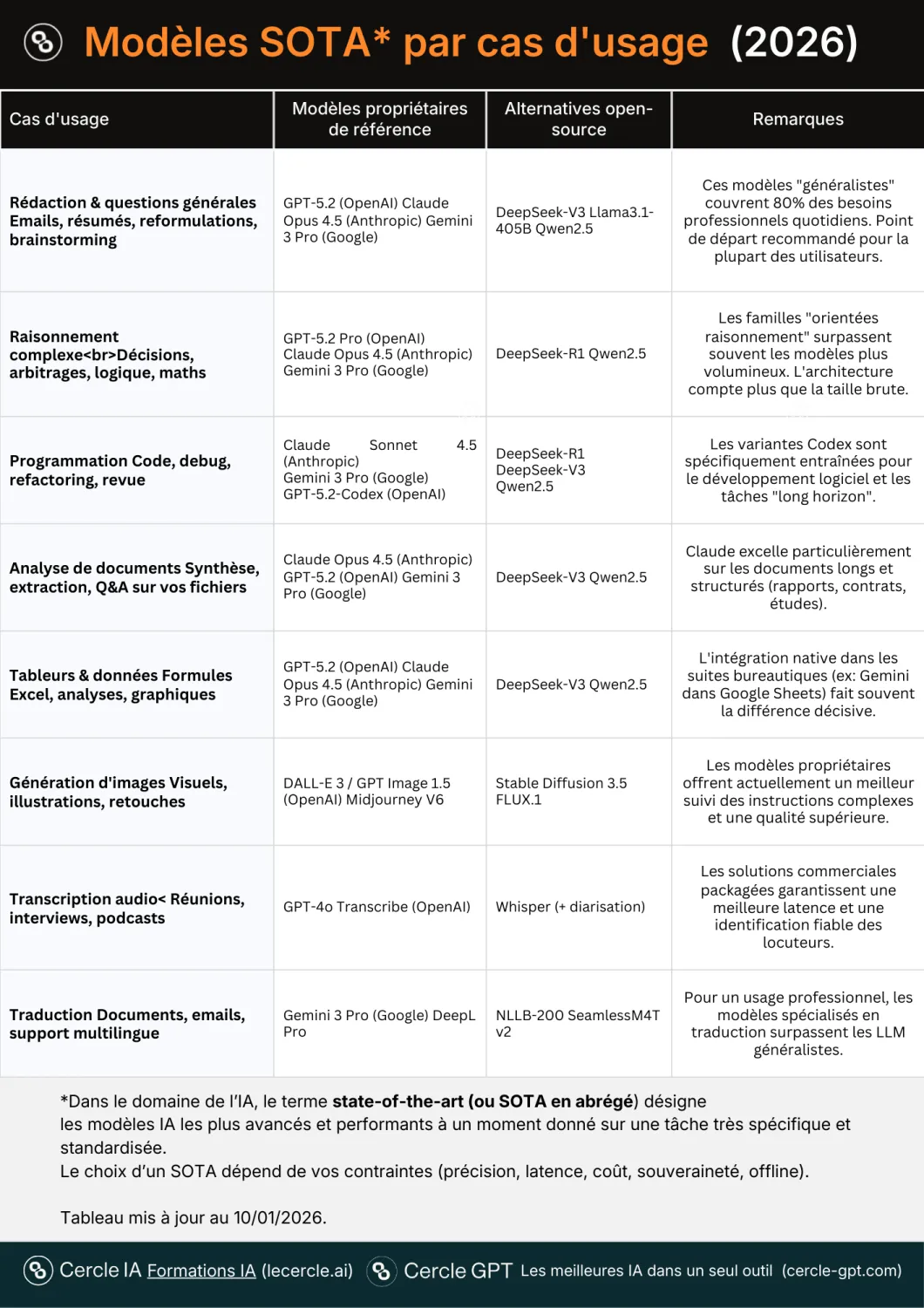
In the AI field, the term state-of-the-art (SOTA) refers to the most advanced and best-performing models at a given moment on a very specific task. It is a highly contested title in perpetual evolution.
AI tool of the week: LMarena
How do you know which AI model is truly the best? Not by reading the press releases from the labs. By asking users.
That is exactly what LMarena (formerly Chatbot Arena) does, a platform created by researchers at the University of California at Berkeley.
LMarena publishes an AI model ranking based on more than 5 million votes from real users. The principle is simple: two anonymous models answer the same question, you choose the best answer, and your vote feeds an Elo score (as in chess).
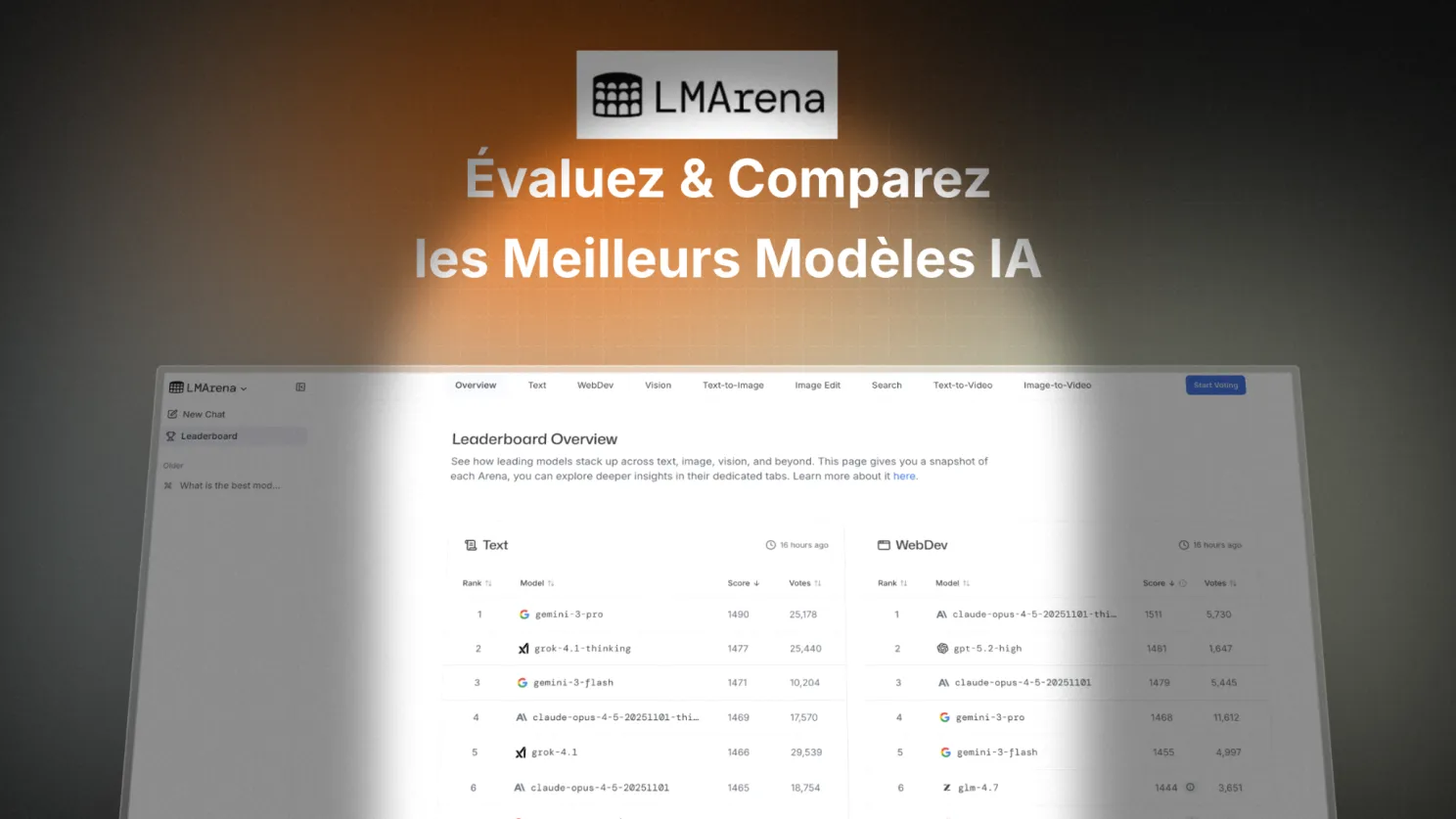
This ranking has three advantages over traditional benchmarks:
- It reflects real-world usage, not lab tests.
- It is updated continuously.
- It allows filtering by category (code, reasoning, creativity, French…).
Test it yourself:
- Battle Mode: ask a question, two anonymous models answer, you vote. Identities are revealed afterwards.
- Direct Mode: access GPT-4o, Claude, Gemini and others for free, without a subscription.
My advice: consult the ranking to identify current leaders. Then spend 15 minutes in Battle Mode with questions from your professional day-to-day.
Access LMarena: https://lmarena.ai/fr/leaderboard (free, no registration required)
Asking “which is the best AI model?” is equivalent to asking “who was the best athlete of antiquity?” The answer has not changed in 2,800 years: it depends on the discipline and the context.
See you soon, and do not forget to put your knowledge into practice.
