
Bienvenue dans cette édition #06 de la newsletter du Cercle IA, la première de l’année 2026. Je vous souhaite une excellente année, riche en apprentissages et en expérimentations.
Et quel meilleur moment pour franchir un cap symbolique : vous êtes désormais plus de 1 000 à suivre cette newsletter. Merci à toutes celles et ceux qui lisent, partagent et commentent depuis le lancement.
« Quel est le meilleur modèle d’IA ? ».
C’est LA question qui revient à chaque formation IA que je donne. Ma réponse déçoit souvent : « Ça dépend. »
Pas parce que je refuse de trancher. Mais parce qu’elle part d’un postulat erroné : qu’il existerait un “meilleur” modèle, universel, optimal pour tous les usages.
C’est comme demander quel est le meilleur athlète olympique. Le sprinter ? Le marathonien ? Le lanceur de javelot ? La réponse dépend de l’épreuve.
Dans cette édition :
- Le podium ne dit pas tout : pourquoi les classements d’IA sont utiles mais insuffisants
- Les disciplines olympiques de l’IA : comprendre où chaque modèle excelle
- Les 7 formes de “dopage” : ce qui fausse les benchmarks et les classements
- L’outil à tester : LMarena, l’arène où vous jugez les modèles vous-même
De l’Olympie antique aux arènes numériques
776 avant J.-C., Olympie, Grèce. Coroebus d’Élis franchit la ligne d’arrivée du stadion. Il devient le premier champion olympique de l’histoire. Mais était-il le meilleur athlète ?
Les Grecs savaient déjà que non. C’est pourquoi ils ont créé le pentathlon : course, saut en longueur, lancer du disque, lancer du javelot, lutte. Le vrai champion devait exceller dans plusieurs disciplines.
Cette obsession de la mesure objective s’est incarnée dans la devise olympique : Citius, Altius, Fortius : plus vite, plus haut, plus fort.
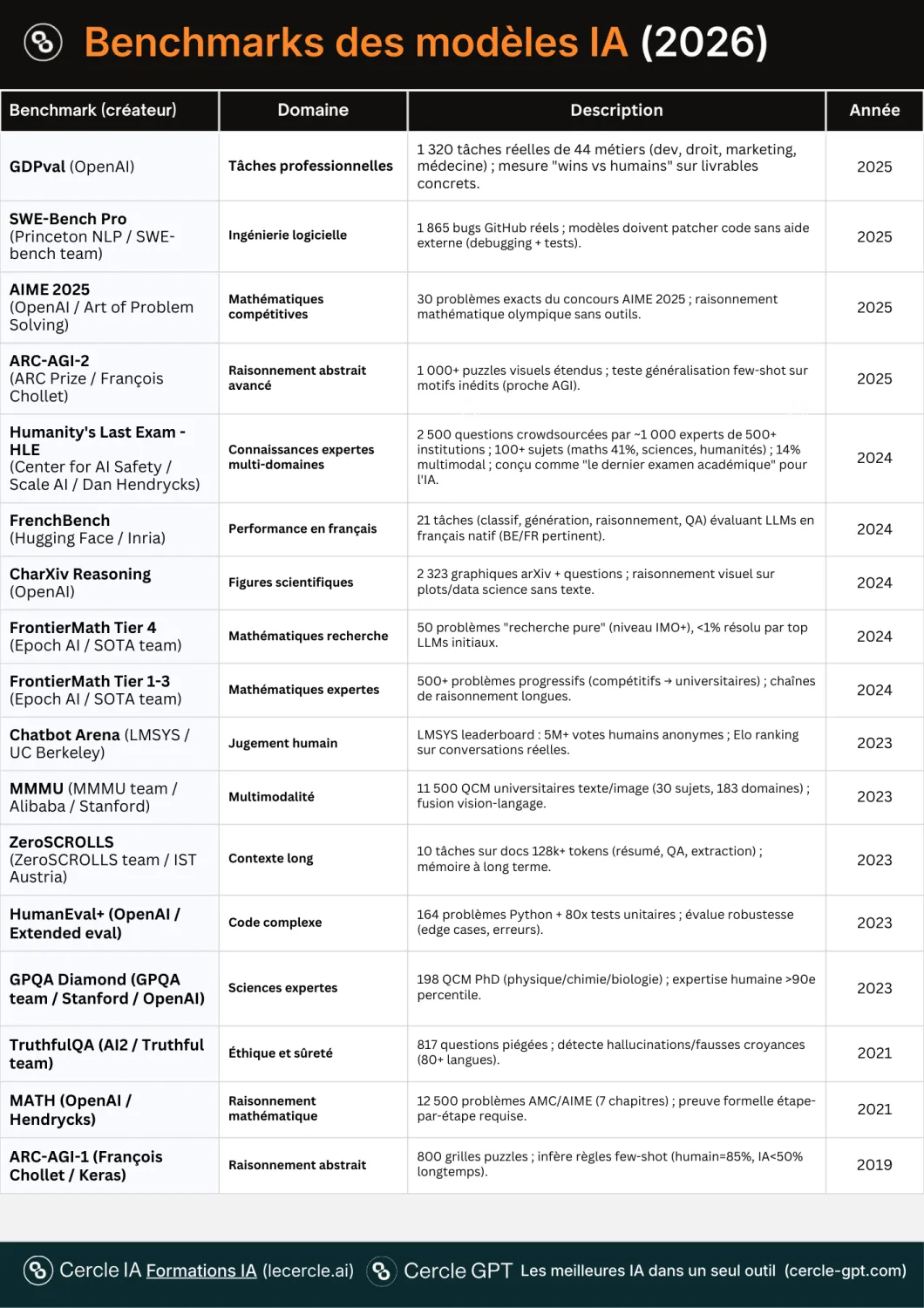
Les benchmarks IA : l’obsession de mesurer l’intelligence des modèles IA
Contrairement à un sprinter, on ne peut pas simplement chronométrer une IA. L’intelligence n’est pas unidimensionnelle.
C’est pourquoi les chercheurs ont créé des benchmarks, des tests standardisés pour mesurer différentes capacités : compréhension du langage, raisonnement logique, génération de code, analyse visuelle, créativité, honnêteté.
2018-2020 : L’ère du “stadion” (GLUE benchmark)
GLUE (General Language Understanding Evaluation) a été lancé en janvier 2018 pour mesurer la compréhension réelle du langage naturel. Comme le stadion, les premiers benchmarks mesuraient une chose : la compréhension du langage. Mais excellente compréhension ≠ bon raisonnement ≠ bon code ≠ bonne créativité.
2020-2023 : L’ère du pentathlon (diversification des benchmarks)
La communauté IA a reconnu que les modèles avaient plusieurs « muscles » à mesurer :
- MMLU : connaissances générales (57 domaines, du droit à la médecine)
- HumanEval : génération de code
- BBH : raisonnement complexe
- HELM : évaluation holistique sur 42 scénarios
2023-2025 : L’ère des Jeux modernes de l’IA
À l’instar des JO de Paris 2024 qui ont réuni 32 sports et 329 épreuves, on recense aujourd’hui plus de 50 benchmarks de modèles IA. Et il n’existe pas de modèle IA champion universel. Chaque discipline révèle son propre podium.
Sept formes de « dopage » des modèles IA
Ben Johnson, 1988, Séoul. Record du monde. Médaille d’or. Puis déchéance : contrôle antidopage positif, titre retiré.
Dans l’IA, des pratiques comparables biaisent les benchmarks :
- Contamination des données : les modèles ont souvent vu les questions des benchmarks pendant leur entraînement. Ils récitent, pas raisonnent.
- Sur-apprentissage des benchmarks : les modèles sont ajustés pour réussir des tests précis, au détriment de leur comportement hors benchmark.
- Sélection stratégique des résultats : les laboratoires mettent en avant les benchmarks favorables et ignorent les autres.
- Biais de conception des benchmarks : certains tests avantagent certaines architectures ou familles de modèles.
- Absence d’arbitrage et de gouvernance : pas de limitation du nombre de tentatives, ni procédure de recours.
- Saturation et obsolescence des benchmarks : beaucoup restent figés alors que les modèles progressent vite.
- Biais des données et domination linguistique : la surreprésentation de l’anglais fausse les résultats.
Ces failles brouillent le signal scientifique. Les chercheurs écrivent que les pratiques actuelles d’évaluation sont un « champ de mines ».
SOTA : le podium mouvant des modèles IA de pointe
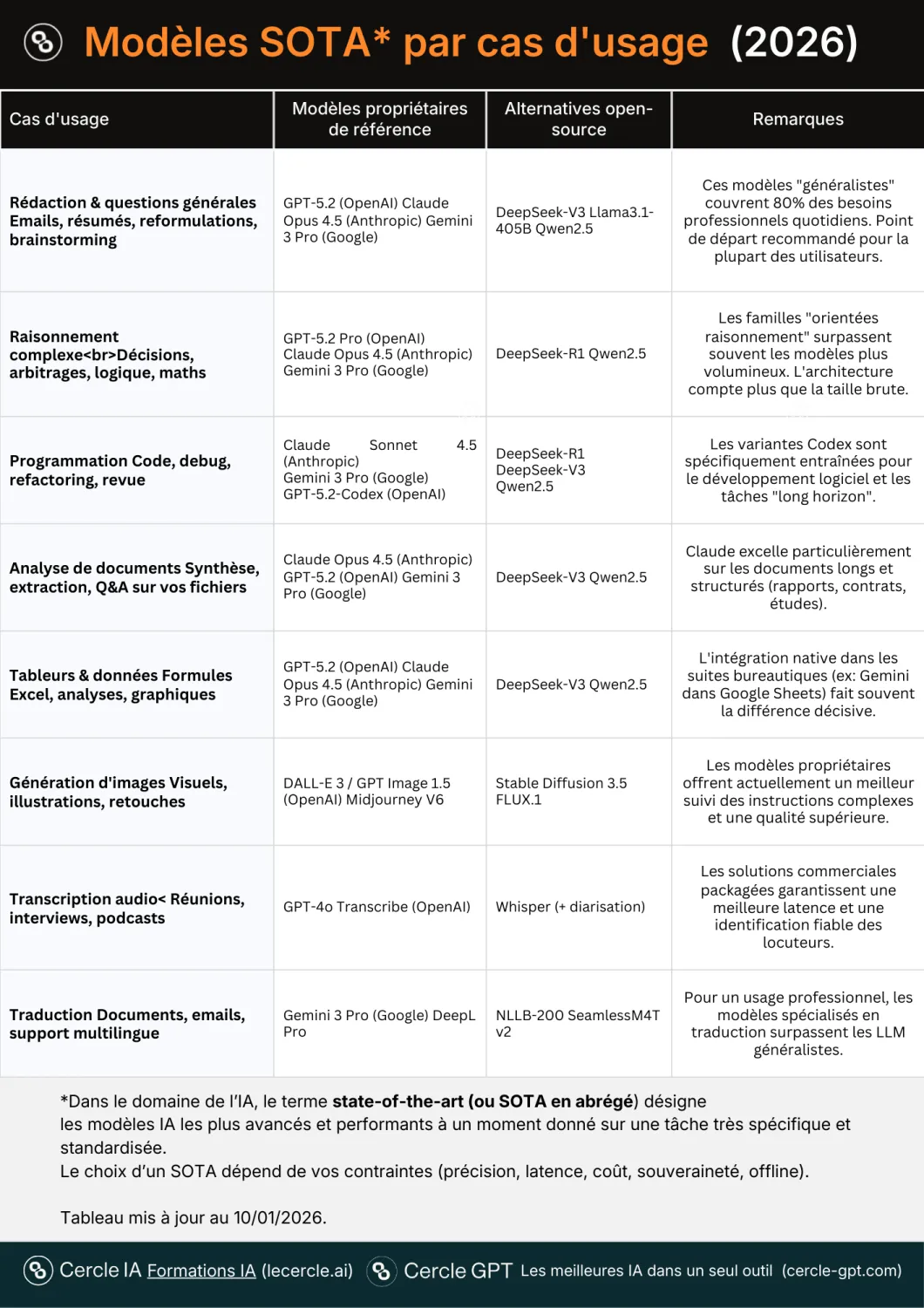
Dans le domaine de l’IA, le terme state-of-the-art (SOTA) désigne les modèles les plus avancés et performants à un moment donné sur une tâche très spécifique. C’est un titre très disputé et en évolution perpétuelle.
L’outil IA de la semaine : LMarena
Comment savoir quel modèle d’IA est vraiment le meilleur ? Pas en lisant les communiqués de presse des laboratoires. En demandant aux utilisateurs.
C’est exactement ce que fait LMarena (anciennement Chatbot Arena), une plateforme créée par des chercheurs de l’Université de Californie à Berkeley.
LMarena publie un classement des modèles d’IA basé sur plus de 5 millions de votes d’utilisateurs réels. Le principe est simple : deux modèles anonymes répondent à la même question, vous choisissez la meilleure réponse, et votre vote alimente un score Elo (comme aux échecs).
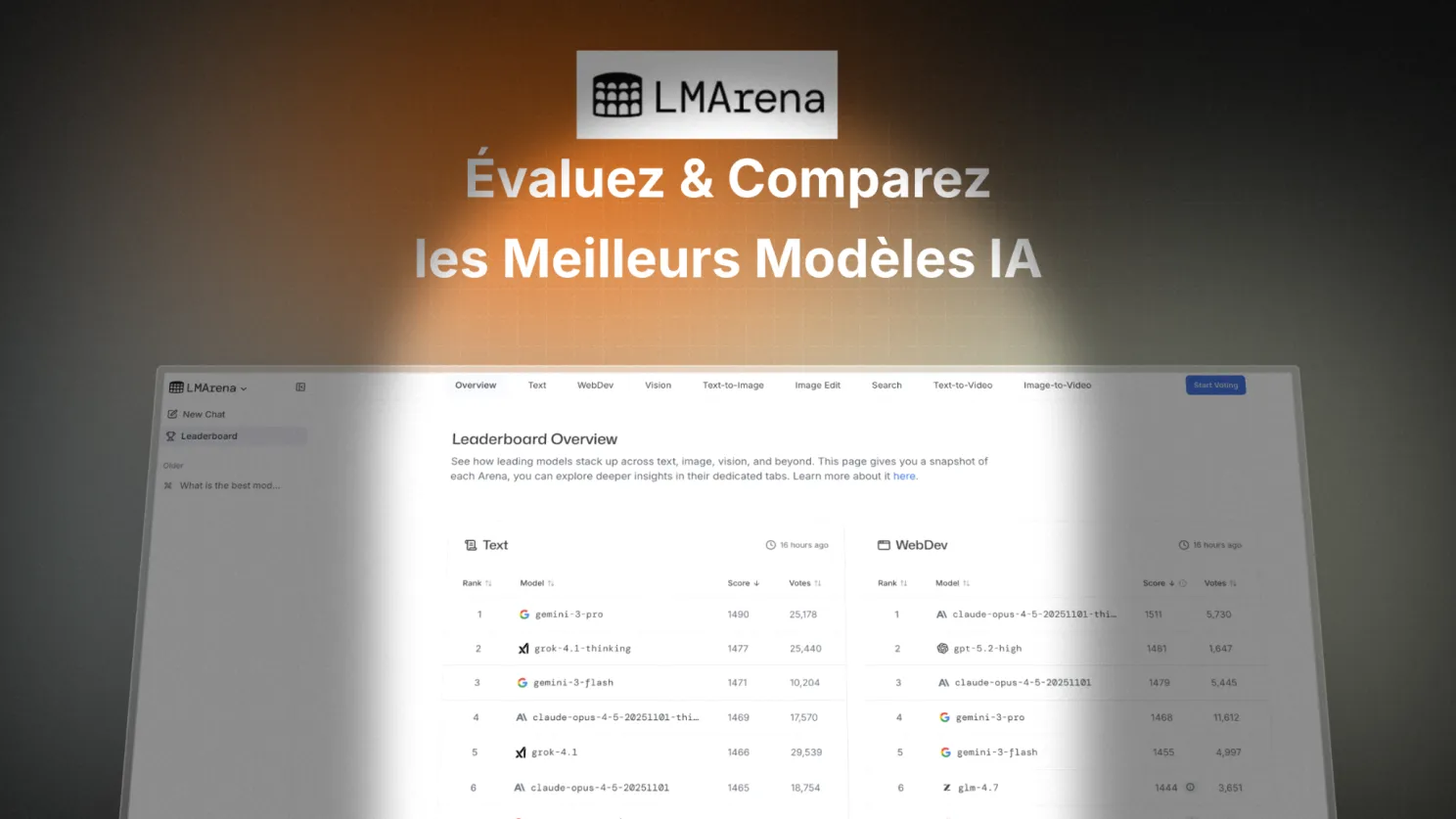
Ce classement a trois avantages sur les benchmarks traditionnels :
- Il reflète l’usage réel, pas des tests de laboratoire.
- Il est mis à jour en continu.
- Il permet de filtrer par catégorie (code, raisonnement, créativité, français…).
Testez vous-même :
- Mode Battle : posez une question, deux modèles anonymes répondent, vous votez. Les identités sont révélées après.
- Mode Direct : accédez gratuitement à GPT-4o, Claude, Gemini et d’autres, sans abonnement.
Mon conseil : consultez le classement pour identifier les leaders actuels. Puis passez 15 minutes en mode Battle avec des questions de votre quotidien professionnel.
Accéder à LMarena : https://lmarena.ai/fr/leaderboard (gratuit, sans inscription)
Poser la question “quel est le meilleur modèle d’IA ?”, ça équivaut à demander : “qui était le meilleur athlète de l’Antiquité ?” La réponse n’a pas changé en 2800 ans : ça dépend de la discipline et du contexte.
À bientôt, et n’oubliez pas de mettre vos connaissances en pratique.
